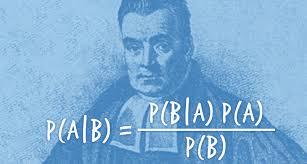
Thu August 31 - Tue November 14, 2017
Introduction to Python for Data Science: Coding the Naive Bayes Algorithm
SEE EVENT DETAILS
About the Event:
Data scientists need to know how to code, and Python is the most useful and versatile programming language for doing data science.
In this practical data science Meetup, you’ll learn foundational skills for adding Python to your data science and analytics toolbox. A professional instructor from Galvanize’s Data Science Immersive program will guide you through writing your first machine learning algorithm (Naive Bayes) in Python from scratch. You'll learn how the algorithm works, where it can be used, and you'll get a chance to run it on real text data. You’ll leave this session equipped to write your own Python scripts to analyze data, and instructor recommendations about next steps to take on your pathway to data science.
Prerequisites:
This Meetup is for beginners and does not require prior programming experience or in-depth knowledge of statistics or probability. Participants who are familiar with concepts of data analysis, statistics, and probability will be better equipped to apply their skills after the conclusion of this meetup. Please have anaconda installed on your computer and know how to run basic commands in a Jupyter (IPython) notebook.
What to Bring:
Bring your laptop and charger. What we're doing will work on a Windows machine, but support from our instructor can only be provided for Mac and Linux users.
Light snacks will be provided.
What You’ll Learn:
• How to write and run Python scripts• How to read data files into Python and analyze them• Which libraries and packages are most useful for analyzing data in Python (especially text data)• Why Python is a flexible, versatile language for doing data science• Which resources you should next utilize to develop your skills
Schedule:
6:00 pm – Doors open, Networking & Snacking
6:15 pm – Lesson Kickoff, Working with Python
6:45 pm – Introduction to supervised machine learning
7:15 pm - Introduction to the Naive Bayes algorithm
7:45 pm – Coding Naive Bayes in Python, classifying text data
9:00 pm – Wrap-Up and Additional Resources
Meet Your Instructor:
Dan Wiesenthal holds two degrees from Stanford University, an MS in Computer Science and a BS in Symbolic Systems. His passion, in a nutshell, is to combine sophisticated algorithms with user-friendly design. As a grad student, he pursued dual concentrations in Human Computer Interaction (HCI) and Artificial Intelligence (AI). With an undergrad background in linguistics, logic, cognitive psychology, and computer science, his research creatively wove together the fields of AI, HCI, Natural Language Processing, Network Analysis, and Machine Learning. For example, Dan, along with two good friends, published one of the first papers analyzing the flow of sentiment through large-scale networks. Since leaving academia, Dan has helped bring a series of early-stage startups from the 0 to 1 stage, going from initial database and server setup all the way through to the nth revision of algorithms for prediction, classification, recommendation, and more. In 2016 Dan joined Galvanize as a lead instructor in the Data Science Immersive in order to support the next generation of data scientists and push the needle on what it means to be a data scientist in industry.
About Galvanize:
Galvanize is the premiere dynamic learning community for technology. With campuses located in booming technology sectors throughout the country, Galvanize provides a community for each the following:
Education - part-time and full-time training in web development, data science, and data engineering
Workspace - whether you’re a freelancer, startup, or established business, we provide beautiful spaces with a community dedicated to support your company’s growth
Networking - events in the tech industry happen constantly in our campuses, ranging from popular Meetups to multi-day international conferences
To learn more about Galvanize, visit galvanize.com.
show less
Data scientists need to know how to code, and Python is the most useful and versatile programming language for doing data science.
In this practical data science Meetup, you’ll learn foundational skills for adding Python to your data science and analytics toolbox. A professional instructor from Galvanize’s Data Science Immersive program will guide you through writing your first machine learning algorithm (Naive Bayes) in Python from scratch. You'll learn how the algorithm works, where it can be used, and you'll get a chance to run it on real text data. You’ll leave this session equipped to write your own Python scripts to analyze data, and instructor recommendations about next steps to take on your pathway to data science.
Prerequisites:
This Meetup is for beginners and does not require prior programming experience or in-depth knowledge of statistics or probability. Participants who are familiar with concepts of data analysis, statistics, and probability will be better equipped to apply their skills after the conclusion of this meetup. Please have anaconda installed on your computer and know how to run basic commands in a Jupyter (IPython) notebook.
What to Bring:
Bring your laptop and charger. What we're doing will work on a Windows machine, but support from our instructor can only be provided for Mac and Linux users.
Light snacks will be provided.
What You’ll Learn:
• How to write and run Python scripts• How to read data files into Python and analyze them• Which libraries and packages are most useful for analyzing data in Python (especially text data)• Why Python is a flexible, versatile language for doing data science• Which resources you should next utilize to develop your skills
Schedule:
6:00 pm – Doors open, Networking & Snacking
6:15 pm – Lesson Kickoff, Working with Python
6:45 pm – Introduction to supervised machine learning
7:15 pm - Introduction to the Naive Bayes algorithm
7:45 pm – Coding Naive Bayes in Python, classifying text data
9:00 pm – Wrap-Up and Additional Resources
Meet Your Instructor:
Dan Wiesenthal holds two degrees from Stanford University, an MS in Computer Science and a BS in Symbolic Systems. His passion, in a nutshell, is to combine sophisticated algorithms with user-friendly design. As a grad student, he pursued dual concentrations in Human Computer Interaction (HCI) and Artificial Intelligence (AI). With an undergrad background in linguistics, logic, cognitive psychology, and computer science, his research creatively wove together the fields of AI, HCI, Natural Language Processing, Network Analysis, and Machine Learning. For example, Dan, along with two good friends, published one of the first papers analyzing the flow of sentiment through large-scale networks. Since leaving academia, Dan has helped bring a series of early-stage startups from the 0 to 1 stage, going from initial database and server setup all the way through to the nth revision of algorithms for prediction, classification, recommendation, and more. In 2016 Dan joined Galvanize as a lead instructor in the Data Science Immersive in order to support the next generation of data scientists and push the needle on what it means to be a data scientist in industry.
About Galvanize:
Galvanize is the premiere dynamic learning community for technology. With campuses located in booming technology sectors throughout the country, Galvanize provides a community for each the following:
Education - part-time and full-time training in web development, data science, and data engineering
Workspace - whether you’re a freelancer, startup, or established business, we provide beautiful spaces with a community dedicated to support your company’s growth
Networking - events in the tech industry happen constantly in our campuses, ranging from popular Meetups to multi-day international conferences
To learn more about Galvanize, visit galvanize.com.
About the Event:
Data scientists need to know how to code, and Python is the most useful and versatile programming language for doing data science.
In this practical data science Meetup, you’ll learn foundational skills for adding Python to your data science and analytics toolbox. A professional instructor from Galvanize’s Data Science Immersive program will guide you through writing your first machine learning algorithm (Naive Bayes) in Python from scratch. You'll learn how the algorithm works, where it can be used, and you'll get a chance to run it on real text data. You’ll leave this session equipped to write your own Python scripts to analyze data, and instructor recommendations about next steps to take on your pathway to data science.
Prerequisites:
This Meetup is for beginners and does not require prior programming experience or in-depth knowledge of statistics or probability. Participants who are familiar with concepts of data analysis, statistics, and probability will be better equipped to apply their skills after the conclusion of this meetup. Please have anaconda installed on your computer and know how to run basic commands in a Jupyter (IPython) notebook.
What to Bring:
Bring your laptop and charger. What we're doing will work on a Windows machine, but support from our instructor can only be provided for Mac and Linux users.
Light snacks will be provided.
What You’ll Learn:
• How to write and run Python scripts• How to read data files into Python and analyze them• Which libraries and packages are most useful for analyzing data in Python (especially text data)• Why Python is a flexible, versatile language for doing data science• Which resources you should next utilize to develop your skills
Schedule:
6:00 pm – Doors open, Networking & Snacking
6:15 pm – Lesson Kickoff, Working with Python
6:45 pm – Introduction to supervised machine learning
7:15 pm - Introduction to the Naive Bayes algorithm
7:45 pm – Coding Naive Bayes in Python, classifying text data
9:00 pm – Wrap-Up and Additional Resources
Meet Your Instructor:
Dan Wiesenthal holds two degrees from Stanford University, an MS in Computer Science and a BS in Symbolic Systems. His passion, in a nutshell, is to combine sophisticated algorithms with user-friendly design. As a grad student, he pursued dual concentrations in Human Computer Interaction (HCI) and Artificial Intelligence (AI). With an undergrad background in linguistics, logic, cognitive psychology, and computer science, his research creatively wove together the fields of AI, HCI, Natural Language Processing, Network Analysis, and Machine Learning. For example, Dan, along with two good friends, published one of the first papers analyzing the flow of sentiment through large-scale networks. Since leaving academia, Dan has helped bring a series of early-stage startups from the 0 to 1 stage, going from initial database and server setup all the way through to the nth revision of algorithms for prediction, classification, recommendation, and more. In 2016 Dan joined Galvanize as a lead instructor in the Data Science Immersive in order to support the next generation of data scientists and push the needle on what it means to be a data scientist in industry.
About Galvanize:
Galvanize is the premiere dynamic learning community for technology. With campuses located in booming technology sectors throughout the country, Galvanize provides a community for each the following:
Education - part-time and full-time training in web development, data science, and data engineering
Workspace - whether you’re a freelancer, startup, or established business, we provide beautiful spaces with a community dedicated to support your company’s growth
Networking - events in the tech industry happen constantly in our campuses, ranging from popular Meetups to multi-day international conferences
To learn more about Galvanize, visit galvanize.com.
read more
Data scientists need to know how to code, and Python is the most useful and versatile programming language for doing data science.
In this practical data science Meetup, you’ll learn foundational skills for adding Python to your data science and analytics toolbox. A professional instructor from Galvanize’s Data Science Immersive program will guide you through writing your first machine learning algorithm (Naive Bayes) in Python from scratch. You'll learn how the algorithm works, where it can be used, and you'll get a chance to run it on real text data. You’ll leave this session equipped to write your own Python scripts to analyze data, and instructor recommendations about next steps to take on your pathway to data science.
Prerequisites:
This Meetup is for beginners and does not require prior programming experience or in-depth knowledge of statistics or probability. Participants who are familiar with concepts of data analysis, statistics, and probability will be better equipped to apply their skills after the conclusion of this meetup. Please have anaconda installed on your computer and know how to run basic commands in a Jupyter (IPython) notebook.
What to Bring:
Bring your laptop and charger. What we're doing will work on a Windows machine, but support from our instructor can only be provided for Mac and Linux users.
Light snacks will be provided.
What You’ll Learn:
• How to write and run Python scripts• How to read data files into Python and analyze them• Which libraries and packages are most useful for analyzing data in Python (especially text data)• Why Python is a flexible, versatile language for doing data science• Which resources you should next utilize to develop your skills
Schedule:
6:00 pm – Doors open, Networking & Snacking
6:15 pm – Lesson Kickoff, Working with Python
6:45 pm – Introduction to supervised machine learning
7:15 pm - Introduction to the Naive Bayes algorithm
7:45 pm – Coding Naive Bayes in Python, classifying text data
9:00 pm – Wrap-Up and Additional Resources
Meet Your Instructor:
Dan Wiesenthal holds two degrees from Stanford University, an MS in Computer Science and a BS in Symbolic Systems. His passion, in a nutshell, is to combine sophisticated algorithms with user-friendly design. As a grad student, he pursued dual concentrations in Human Computer Interaction (HCI) and Artificial Intelligence (AI). With an undergrad background in linguistics, logic, cognitive psychology, and computer science, his research creatively wove together the fields of AI, HCI, Natural Language Processing, Network Analysis, and Machine Learning. For example, Dan, along with two good friends, published one of the first papers analyzing the flow of sentiment through large-scale networks. Since leaving academia, Dan has helped bring a series of early-stage startups from the 0 to 1 stage, going from initial database and server setup all the way through to the nth revision of algorithms for prediction, classification, recommendation, and more. In 2016 Dan joined Galvanize as a lead instructor in the Data Science Immersive in order to support the next generation of data scientists and push the needle on what it means to be a data scientist in industry.
About Galvanize:
Galvanize is the premiere dynamic learning community for technology. With campuses located in booming technology sectors throughout the country, Galvanize provides a community for each the following:
Education - part-time and full-time training in web development, data science, and data engineering
Workspace - whether you’re a freelancer, startup, or established business, we provide beautiful spaces with a community dedicated to support your company’s growth
Networking - events in the tech industry happen constantly in our campuses, ranging from popular Meetups to multi-day international conferences
To learn more about Galvanize, visit galvanize.com.
show less
Date/Times:
The Best Events
Every Week in Your Inbox
From Our Sponsors
UPCOMING EVENTS









Great suggestion! We'll be in touch.
Event reviewed successfully.